Here are some depictions of electromagnetic wave, similar to the depictions in other places:

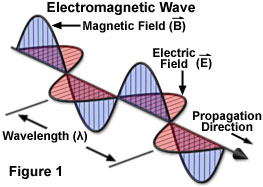

Isn't there an error? It is logical to presume that the electric field should have maximum when magnetic field is at zero and vise versa, so that there is no moment when the both vectors are zero at the same time. Otherwise one comes to a conclusion that the total energy of the system becomes zero, then grows to maximum, then becomes zero again which contradicts the conservation law.
The depictions you're seeing are correct, the electric and magnetic fields both reach their amplitudes and zeroes in the same locations. Rafael's answer and certain comments on it are completely correct; energy conservation does not require that the energy density be the same at every point on the electromagnetic wave. The points where there is no field do not carry any energy. But there is never a time when the fields go to zero everywhere. In fact, the wave always maintains the same shape of peaks and valleys (for an ideal single-frequency wave in a perfect classical vacuum), so the same amount of energy is always there. It just moves.
To add to Rafael's excellent answer, here's an explicit example. Consider a sinusoidal electromagnetic wave propagating in the $z$ direction. It will have an electric field given by
$$\mathbf{E}(\mathbf{r},t) = E_0\hat{\mathbf{x}}\sin(kz - \omega t)$$
Take the curl of this and you get
$$\nabla\times\mathbf{E}(\mathbf{r},t) = \left(\hat{\mathbf{z}}\frac{\partial}{\partial y} - \hat{\mathbf{y}}\frac{\partial}{\partial z}\right)E_0\sin(kz - \omega t) = -E_0 k\hat{\mathbf{y}}\cos(kz - \omega t)$$
Using one of Maxwell's equations, $\nabla\times\mathbf{E} = -\frac{\partial \mathbf{B}}{\partial t}$, you get
$$-\frac{\partial\mathbf{B}(\mathbf{r},t)}{\partial t} = -E_0 k\hat{\mathbf{y}}\cos(kz - \omega t)$$
Integrate this with respect to time to find the magnetic field,
$$\mathbf{B}(\mathbf{r},t) = -\frac{E_0 k}{\omega}\hat{\mathbf{y}}\sin(kz - \omega t)$$
Comparing this with the expression for $\mathbf{E}(\mathbf{r},t)$, you find that $\mathbf{B}$ is directly proportional to $\mathbf{E}$. When and where one is zero, the other will also be zero; when and where one reaches its maximum/minimum, so does the other.
For an electromagnetic wave in free space, conservation of energy is expressed by Poynting's theorem,
$$\frac{\partial u}{\partial t} = -\nabla\cdot\mathbf{S}$$
The left side of this gives you the rate of change of energy density in time, where
$$u = \frac{1}{2}\left(\epsilon_0 E^2 + \frac{1}{\mu_0}B^2\right)$$
and the right side tells you the electromagnetic energy flux density, in terms of the Poynting vector,
$$\mathbf{S} = \frac{1}{\mu_0}\mathbf{E}\times\mathbf{B}$$
Poynting's theorem just says that the rate at which the energy density at a point changes is the opposite of the rate at which energy density flows away from that point.
If you plug in the explicit expressions for the wave in my example, after a bit of algebra you find
$$\frac{\partial u}{\partial t} = -\omega E_0^2\left(\epsilon_0 + \frac{k^2}{\mu_0\omega^2}\right)\sin(kz - \omega t)\cos(kz - \omega t) = -\epsilon_0\omega E_0^2 \sin\bigl(2(kz - \omega t)\bigr)$$
(using $c = \omega/k$) and
$$\nabla\cdot\mathbf{S} = \frac{2}{\mu_0}\frac{k^2}{\omega}E^2 \sin(kz - \omega t)\cos(kz - \omega t) = \epsilon_0 \omega E_0^2 \sin\bigl(2(kz - \omega t)\bigr)$$
thus confirming that the equality in Poynting's theorem holds, and therefore that EM energy is conserved.
Notice that the expressions for both sides of the equation include the factor $\sin\bigl(2(kz - \omega t)\bigr)$ - they're not constant. This mathematically shows you the structure of the energy in an EM wave. It's not just a uniform "column of energy;" the amount of energy contained in the wave varies sinusoidally from point to point ($S$ tells you that), and as the wave passes a particular point in space, the amount of energy it has at that point varies sinusoidally in time ($u$ tells you that). But those changes in energy with respect to space and time don't just come out of nowhere. They're precisely synchronized in the manner specified by Poynting's theorem, so that the changes in energy at a point are accounted for by the flux to and from neighboring points.